Verzia Java verzie 1.1 predstavuje množstvo tried pre prácu so znakmi. Tieto nové triedy vytvárajú abstrakciu na prevod z pojmu znakových hodnôt špecifických pre platformu na Unicode hodnoty. Tento stĺpec sa zameriava na to, čo bolo pridané, a na motivácie pre pridanie týchto tried znakov.
Typ char
Asi najviac zneužívaným základným typom v jazyku C je typ char. The char typu je čiastočne zneužívaný, pretože je definovaný ako 8 bitov a za posledných 25 rokov 8 bitov definoval aj najmenší nedeliteľný kúsok pamäte v počítačoch. Keď skombinujete druhú skutočnosť so skutočnosťou, že znaková sada ASCII bola definovaná tak, aby sa zmestila do 7 bitov, znak char typ je veľmi pohodlný „univerzálny“ typ. Ďalej v C ukazovateľ na premennú typu char sa stal typom univerzálneho ukazovateľa, pretože všetko, na čo sa dalo odkazovať ako char sa dá pomocou castingu tiež označiť ako akýkoľvek iný typ.
Používanie a zneužívanie char typ v jazyku C viedol k mnohým nekompatibilitám medzi implementáciami kompilátora, takže v štandarde ANSI pre jazyk C boli urobené dve konkrétne zmeny: Univerzálny ukazovateľ bol predefinovaný tak, aby mal typ prázdnoty, čo si vyžadovalo výslovné vyhlásenie programátora; a číselná hodnota znakov sa považovala za podpísanú, čím sa definovalo, ako sa s nimi bude zaobchádzať, keď sa použijú v numerických výpočtoch. Potom v polovici 80. rokov inžinieri a používatelia prišli na to, že 8 bitov nestačí na to, aby predstavovali všetky postavy na svete. Bohužiaľ, v tom čase bolo C už také zakorenené, že ľudia neboli ochotní, ba dokonca nedokázali zmeniť definíciu pojmu char typu. Teraz blikajte dopredu do 90. rokov, do raných začiatkov Javy. Jedným z mnohých princípov stanovených v dizajne jazyka Java bolo, že znaky budú 16 bitové. Táto voľba podporuje použitie Unicode, štandardný spôsob reprezentácie mnohých rôznych druhov znakov v mnohých rôznych jazykoch. Nanešťastie to tiež pripravilo pôdu pre rôzne problémy, ktoré sa až teraz odstraňujú.
Čo je to vlastne postava?
Vedel som, že mám ťažkosti, keď som sa ocitol pri kladení otázky: „No a čo je postava? "No, postava je písmeno, nie? Veľa písmen tvorí slovo, slová tvoria vety atď. Realita však je, že vzťah medzi zobrazením postavy na obrazovke počítača , nazval jeho glyf, na číselnú hodnotu, ktorá určuje daný glyf, nazývaný a kódový bod, nie je vôbec vôbec priamy.
Považujem za šťastie, že som rodeným hovorcom anglického jazyka. Po prvé preto, lebo to bol spoločný jazyk významného počtu tých, ktorí prispeli k návrhu a vývoju moderného digitálneho počítača; po druhé, pretože má relatívne malý počet glyfov. V definícii ASCII je 96 tlačiteľných znakov, ktoré možno použiť na písanie angličtiny. Porovnajte to s čínštinou, kde je definovaných viac ako 20 000 glyfov a táto definícia je neúplná. Od raných začiatkov v Morseovom a Baudotovom kóde sa z celkovej jednoduchosti (niekoľko znakov, štatistická frekvencia prejavov) anglického jazyka stala lingua-franca digitálneho veku. S nárastom počtu ľudí vstupujúcich do digitálneho veku sa však zvyšoval aj počet rodených hovoriacich anglicky. Ako čísla rástli, čoraz viac ľudí bolo čoraz menej ochotných akceptovať, že počítače používajú ASCII a hovoria iba anglicky. To výrazne zvýšilo počet „znakových“ počítačov potrebných na pochopenie. Vo výsledku sa musel počet znakov kódovaných počítačmi zdvojnásobiť.
Počet dostupných znakov sa zdvojnásobil, keď bol ctihodný 7-bitový kód ASCII začlenený do 8-bitového kódovania znakov s názvom ISO Latin-1 (alebo ISO 8859_1, pričom „ISO“ je Medzinárodná organizácia pre normalizáciu). Ako ste sa mohli zoznámiť s kódovacím názvom, tento štandard umožňoval reprezentáciu mnohých jazykov odvodených z latinčiny používaných na európskom kontinente. To, že štandard bol vytvorený, však ešte neznamená, že je použiteľný. V tom čase už veľa počítačov začalo používať ďalších 128 „znakov“, ktoré mohli byť s výhodou spojené s 8-bitovým znakom. Dva dochované príklady použitia týchto ďalších znakov sú osobný počítač IBM (PC) a najpopulárnejší počítačový terminál vôbec, Digital Equipment Corporation VT-100. Ten žije ďalej vo forme softvéru terminálového emulátora.
O skutočnom čase smrti 8-bitovej postavy sa bude nepochybne diskutovať po celé desaťročia, ale zafixujem to pri predstavení počítača Macintosh v roku 1984. Macintosh priniesol do hlavného prúdu výpočtov dva veľmi revolučné koncepty: znakové písma, ktoré boli uložené v RAM; a WorldScript, ktoré môžu byť použité na reprezentáciu znakov v akomkoľvek jazyku. Samozrejme, išlo iba o kópiu toho, čo spoločnosť Xerox dodávala na svojich strojoch triedy Púpava vo forme textového systému Star, ale Macintosh priniesol tieto nové znakové sady a písma publiku, ktoré stále používalo „hlúpe“ terminály . Po spustení nebolo možné zastaviť používanie rôznych typov písma - bolo to príliš príťažlivé pre príliš veľa ľudí. Koncom 80. rokov tlak na štandardizáciu používania všetkých týchto znakov vyvrcholil vznikom konzorcia Unicode, ktoré vydalo svoju prvú špecifikáciu v roku 1990. Bohužiaľ, v 80. rokoch a dokonca až v 90. rokoch vynásobený počet znakových sád. Len veľmi málo z inžinierov, ktorí v tom čase vytvárali nové kódy znakov, považovalo rodiaci sa štandard Unicode za životaschopný, a preto vytvorili svoje vlastné priradenia kódov k glyfom. Takže aj keď Unicode nebol dobre prijatý, predstava, že k dispozícii bolo iba 128 alebo najviac 256 znakov, bola definitívne preč. Po systéme Macintosh sa podpora rôznych typov písma stala nevyhnutnou funkciou spracovania textu. Osem bitových postáv vymieralo.
Java a Unicode
Do príbehu som vstúpil v roku 1992, keď som sa v spoločnosti Sun pripojil k skupine Oak (jazyk Java sa pri prvom vývoji nazýval Oak). Základný typ char bol definovaný ako 16 nepodpísaných bitov, jediný nepodpísaný typ v Jave. Odôvodnenie pre 16-bitový znak bolo, že bude podporovať ľubovoľnú reprezentáciu znakov Unicode, čím sa stane Java vhodnou na reprezentáciu reťazcov v akomkoľvek jazyku podporovanom Unicode. Ale vedieť reprezentovať reťazec a vedieť ho vytlačiť boli vždy samostatné problémy. Vzhľadom na to, že väčšina skúseností v skupine Oak pochádzala zo systémov Unix a systémov odvodených z Unixu, najpohodlnejšou znakovou sadou bola opäť ISO Latin-1. Taktiež s unixovým dedičstvom skupiny bol systém I / O Java z veľkej časti modelovaný na abstrakcii toku Unix, pričom každé I / O zariadenie bolo možné reprezentovať prúdom 8-bitových bajtov. Táto kombinácia zanechala v jazyku niečo medzi 8-bitovým vstupným zariadením a 16-bitovými znakmi v Jave. Teda kdekoľvek, kde bolo treba čítať alebo zapisovať reťazce Java, do 8-bitového toku, bol tam malý kúsok kódu, hack, ktorý magicky namapoval 8-bitové znaky na 16-bitový unicode.
Vo verziách 1.0 Java Developer Kit (JDK) bol vstupný hack v DataInputStream triedy a výstupný hack bol celý PrintStream trieda. (V skutočnosti bola pomenovaná vstupná trieda TextInputStream vo vydaní Java 2 verzie alfa 2, ale bola nahradená DataInputStream hack v skutočnom vydaní.) Toto naďalej spôsobuje problémy začínajúcim programátorom Java, pretože zúfalo hľadajú Java ekvivalent funkcie C getc (). Zvážte nasledujúci program Java 1.0:
import java.io. *; public class falošný {public static void main (String args []) {FileInputStream fis; DataInputStream dis; char c; try {fis = new FileInputStream ("data.txt"); dis = nový DataInputStream (fis); while (true) {c = dis.readChar (); System.out.print (c); System.out.flush (); if (c == '\ n') break; } fis.close (); } catch (Výnimka e) {} System.exit (0); }} Na prvý pohľad sa zdá, že tento program otvorí súbor, prečíta ho po jednom znaku a ukončí sa pri načítaní prvého nového riadku. V praxi však získate nevyžiadanú poštu. A dôvod, prečo sa vyhadzujete, je ten readChar číta 16-bitové znaky Unicode a System.out.print vypíše to, čo predpokladá, že sú 8-bitové znaky ISO Latin-1. Ak však zmeníte vyššie uvedený program na použitie programu readLine funkcia DataInputStream, zdá sa, že funguje, pretože kód v readLine načíta formát, ktorý je definovaný prechodným kývnutím na špecifikáciu Unicode ako „upravený UTF-8“. (UTF-8 je formát, ktorý Unicode určuje na zastupovanie znakov Unicode v 8-bitovom vstupnom toku.) Situácia v prostredí Java 1.0 je teda taká, že reťazce Java sú zložené zo 16-bitových znakov Unicode, ale existuje iba jedno mapovanie, ktoré mapuje Znaky ISO Latin-1 do Unicode. Našťastie Unicode definuje kódovú stránku „0“ - teda 256 znakov, ktorých horných 8 bitov je nulových - aby presne zodpovedali množine ISO Latin-1. Mapovanie je teda dosť malicherné a pokiaľ používate iba súbory znakov ISO Latin-1, nebudete mať žiadne problémy, keď dáta opustia súbor, je manipulované triedou Java a potom prepísané do súboru .
Pri zakopávaní vstupného konverzného kódu do týchto tried nastali dva problémy: Nie všetky platformy ukladali svoje viacjazyčné súbory v upravenom formáte UTF-8; a určite aplikácie na týchto platformách nemuseli nevyhnutne očakávať latinské znaky v tejto podobe. Preto bola podpora implementácie neúplná a nebolo možné ľahko pridať potrebnú podporu v neskoršom vydaní.
Java 1.1 a Unicode
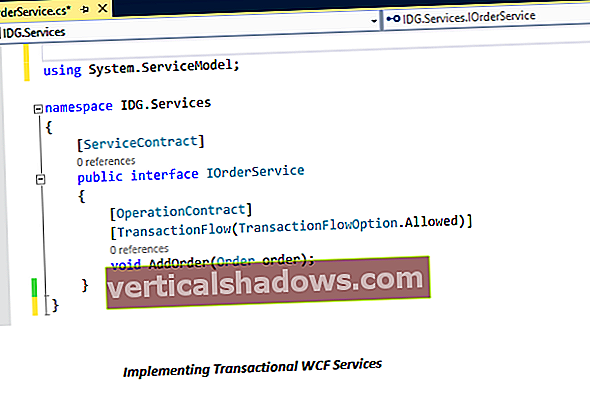
Vydanie Java 1.1 predstavilo úplne novú sadu rozhraní na prácu so znakmi, tzv Čitatelia a Spisovatelia. Upravil som pomenovanú triedu falošný zhora do triedy s názvom v pohode. The v pohode trieda používa InputStreamReader triedy na spracovanie súboru skôr ako DataInputStream trieda. Poznač si to InputStreamReader je podtrieda nového Čitateľ triedy a System.out je teraz a PrintWriter objekt, ktorý je podtriedou Spisovateľ trieda. Kód tohto príkladu je uvedený nižšie:
import java.io. *; public class cool {public static void main (String args []) {FileInputStream fis; Irs InputStreamReader; char c; try {fis = new FileInputStream ("data.txt"); irs = nový InputStreamReader (fis); System.out.println ("Používanie kódovania:" + irs.getEncoding ()); while (true) {c = (char) irs.read (); System.out.print (c); System.out.flush (); if (c == '\ n') break; } fis.close (); } catch (Výnimka e) {} System.exit (0); }} Primárny rozdiel medzi týmto príkladom a predchádzajúcim zoznamom kódov je v použití kódu InputStreamReader triedy skôr ako DataInputStream trieda. Ďalším spôsobom, ktorým sa tento príklad líši od predchádzajúceho, je ďalší riadok, ktorý vytlačí kódovanie použité kódom InputStreamReader trieda.
Dôležitým bodom je, že existujúci kód, ktorý je raz nezdokumentovaný (a zdanlivo nepoznateľný) a je zakomponovaný do implementácie getChar metóda DataInputStream triedy, bola odstránená (v skutočnosti je jej použitie zastarané; bude odstránené v budúcom vydaní). Vo verzii Java verzie 1.1 je mechanizmus, ktorý vykonáva prevod, teraz zapuzdrený v Čitateľ trieda. Toto zapuzdrenie poskytuje knižniciam triedy Java spôsob, ako podporovať mnoho rôznych externých reprezentácií znakov, ktoré nie sú latinské znaky, pričom sa interne používa Unicode.
Samozrejme, rovnako ako pôvodný návrh subsystému I / O, existujú aj symetrické náprotivky tried čítania, ktoré vykonávajú zápis. Trieda OutputStreamWriter možno použiť na zápis reťazcov do výstupného toku, triedy BufferedWriter pridá vrstvu ukladania do vyrovnávacej pamäte atď.
Obchodovanie s bradavicami alebo skutočný pokrok?
Trochu vznešený cieľ dizajnu Čitateľ a Spisovateľtriedy bolo skrotiť to, čo je v súčasnosti hodge-podge štandardov reprezentácie tých istých informácií, poskytnutím štandardného spôsobu prevodu tam a späť medzi starým zastúpením - či už je to Macintosh v gréčtine alebo v azbuke - a Unicode. Trieda Java, ktorá sa zaoberá reťazcami, sa teda nemusí meniť, keď sa pohybuje z platformy na platformu. Toto by mohol byť koniec príbehu, až na to, že teraz, keď je konverzný kód zapuzdrený, vyvstáva otázka, čo tento kód predpokladá.
Pri skúmaní tohto stĺpca mi pripomenuli slávny citát výkonného riaditeľa spoločnosti Xerox (predtým to bol Xerox, keď to bola spoločnosť Haloid Company) o tom, že je kopírka nadbytočná, pretože pre sekretárku bolo pomerne ľahké vložiť kúsok uhlíkového papiera do písacím strojom a pri vytváraní originálu urobila kópiu dokumentu. Z časového hľadiska je samozrejme zrejmé, že fotokopírovací stroj je pre osobu prijímajúcu dokument oveľa výhodnejší ako pre osobu generujúcu dokument. JavaSoft preukázal podobný nedostatočný prehľad o použití tried kódovania a dekódovania znakov pri ich návrhu tejto časti systému.